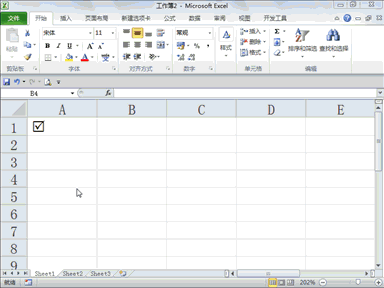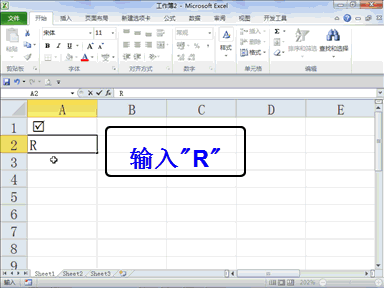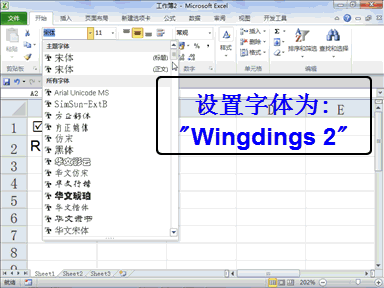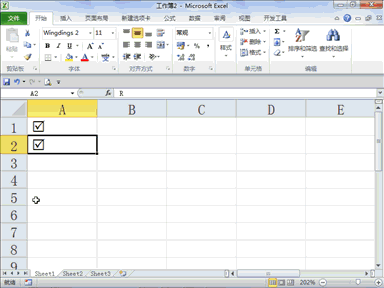
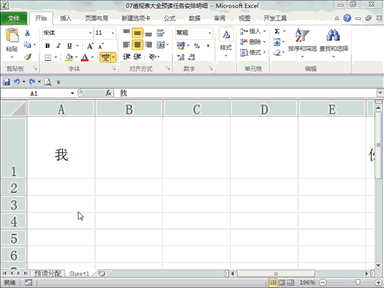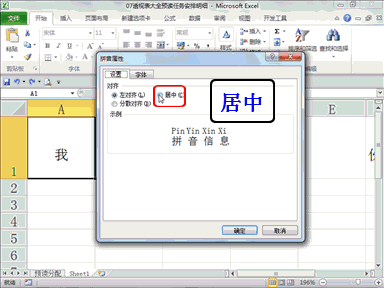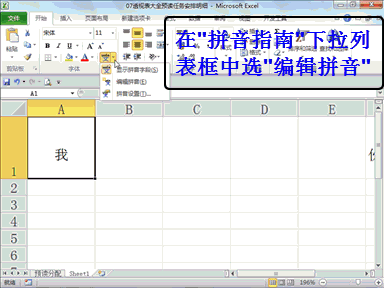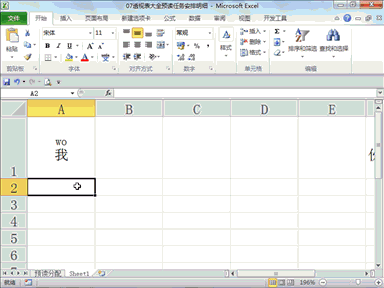
下载贤集网APP入驻自媒体
近日,来自 DeepMind 的科学家在提交给同行评议的期刊《人工智能》(ArtificialIntelligence)上的一篇题为 “Reward is enough” 的论文中认为,人工智能及其相关能力不是通过制定和解决复杂问题而产生的,而是通过坚持一个简单而强大的原则:奖励最大化。 该研究由 DeepMind 首席研究科学家、伦敦大学学院教授 David Silver 领衔,研究灵感源于他们对自然智能的进化研究以及人工智能的最新成就,在撰写论文时仍处于预证明阶段。研究人员认为,奖励最大化和试错经验足以培养表现出与智力相关的能力行为。由此,他们得出结论,强化学习是基于奖励最大化的人工智能分支,可以推动通用人工智能的发展。