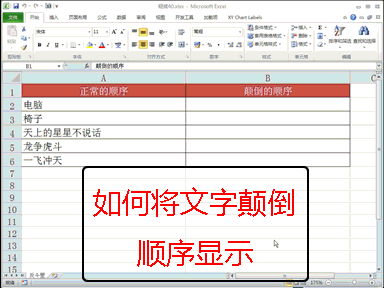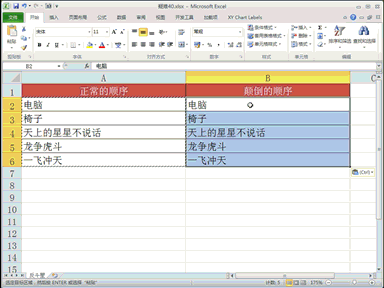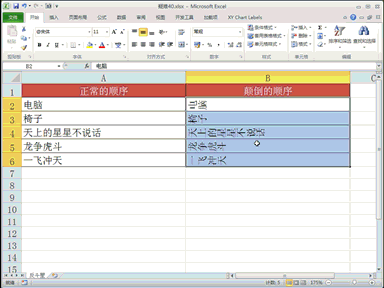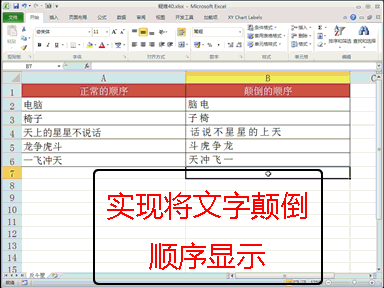
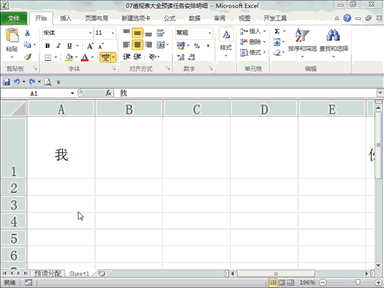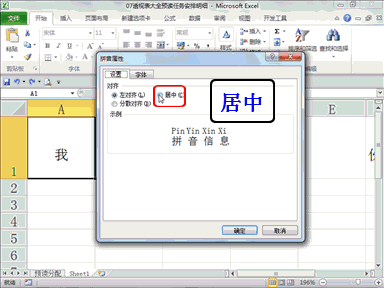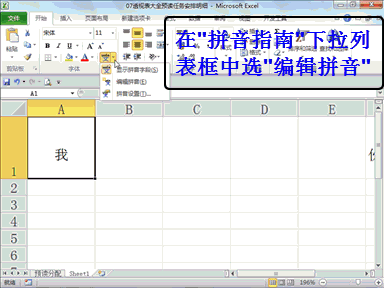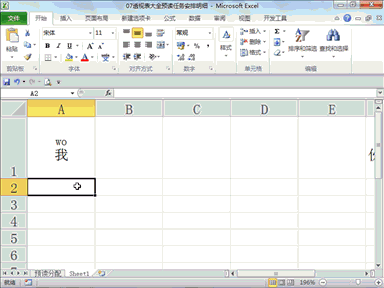
下载贤集网APP入驻自媒体
特拉维夫大学和英伟达研究团队利用CLIP模型的语义能力,提出了一种文本驱动的方法:StyleGAN-NADA,无需在新的领域收集图像,只要有文本提示就能极速生成特定领域图像。凭借文字提示,经过短时间的训练,就可以让生成器适应不同风格和形状的众多领域。 不需要编辑单个图像,使用OpenAI的CLIP信号就可以训练生成器。 论文提出的方法在广泛的域外图像生成中也适用,从风格和纹理变化到形状修改,从现实到幻想,通过一个基于文本的界面就能实现。 就算是最极端的形状变化,只要几分钟的训练也能做到。