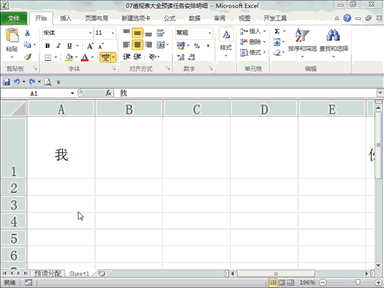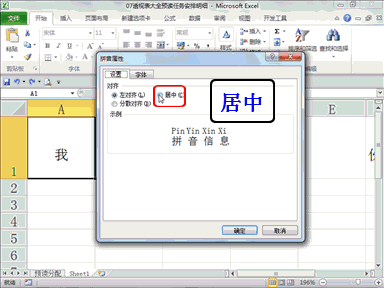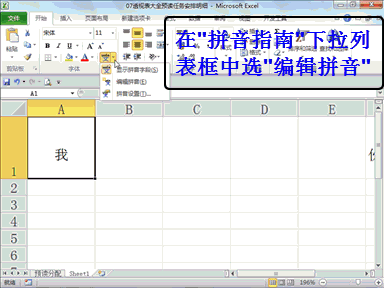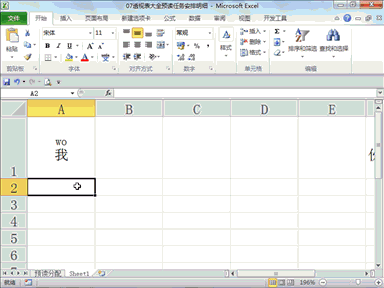
回复安全观察家:从而实现基于注意力机制的动态计算,能够在硬件层面做到“没有输入,没有功耗”,在算法层面做到“有输入时,根据输入重要性程度动态调整计算”,在典型视觉场景任务功耗可低至 0.7 毫瓦



下载贤集网APP入驻自媒体
近日,中国科学院微电子研究所的一项研究提供了一种新的硬件开发路径,可实现高能效和可扩展的神经网络架构。相关论文以《基于磁畴壁隧道结的全自旋神经形态计算硬件中的人工突触和神经元》为题发表在Nature Communications。微电子所博士研究生刘龙为第一作者,微电子所邢国忠研究员、刘明院士为共同通讯作者。 传统的通用计算芯片(如GPU和CPU)主要都是基于冯·诺依曼架构设计。该架构几十年来一直是计算机系统的主流架构。然而,这种设计方式面临着“存储墙”等问题,极大限制了系统的整体效率,特别是在处理大规模数据时。随着计算需求的增加和性能瓶颈的显现,业界也在积极探索新的架构设计,例如神经形态计算。 神经形态计算试图模仿大脑神经元和突触的结构和功能,以实现更高效的并行处理和低功耗计算,能提供传统架构无法比拟的性能和效率。 本次研究中,研究人员成功开发了基于全电控磁畴壁(DW)动力学特性的磁畴壁隧道结(DW-MTJ)器件,并实现了线性权重更新和非线性激活函数功能。实验证明,这些DW-MTJ集成器件能够实现全自旋人工突触和神经元功能,为开发高度可扩展的集成神经形态电路奠定了基础。全自旋意味着所有信号处理都是通过电子的自旋特性完成的,而不是电荷。这种方法可以提高能效和处理速度。