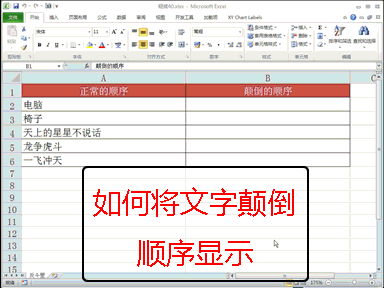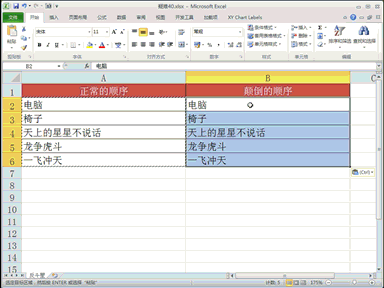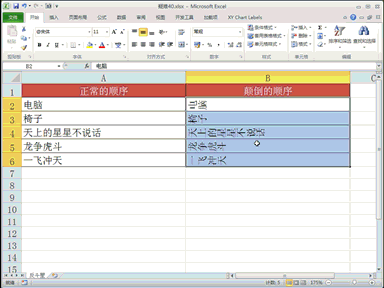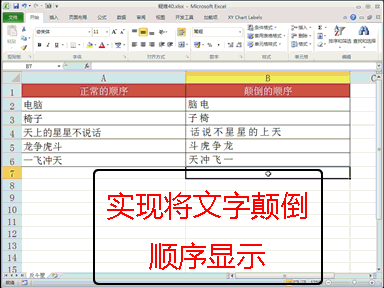
回复IT猿人:对于长序列,Transformer的计算成本往往很高,当长序列变得更长时,RNN会遗忘。TTT训练巧妙地利用神经网络解决RNN的不足。



下载贤集网APP入驻自媒体
一觉醒来,超越 Transformer 和 Mamba 的新架构诞生了? 斯坦福、UCSD、UC 伯克利和 Meta 的研究人员提出了一种全新架构,用机器学习模型取代 RNN 的隐藏状态。 这个模型通过对输入 token 进行梯度下降来压缩上下文,这种方法被称为“测试时间训练层(Test-Time-Training layers,TTT)”。 TTT 层直接替代了注意力机制,解锁了具有表现力记忆的线性复杂度架构,使我们能够在上下文中训练包含数百万(未来可能是数十亿)个 token 的 LLM。 作者相信,这个研究了一年多的项目,将从根本上改变我们的语言模型方法。 而结果证明,TTT-Linear 和 TTT-MLP 直接赶超或击败了最强的 Transformer 和 Mamba! 更令人兴奋的是,虽然目前 TTT 只应用于语言建模,但在未来,它也可以用在长视频上,可谓前景远大。