回复未来X畅想:MIT 揪毛病,数据工具来帮忙。



下载贤集网APP入驻自媒体
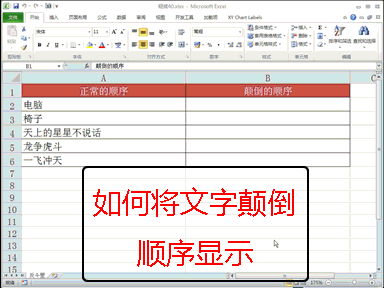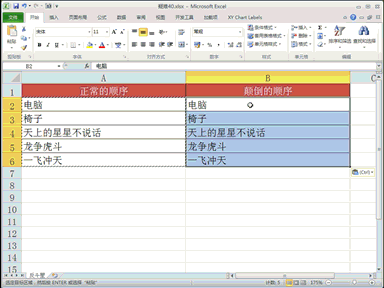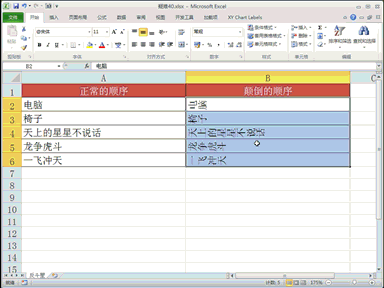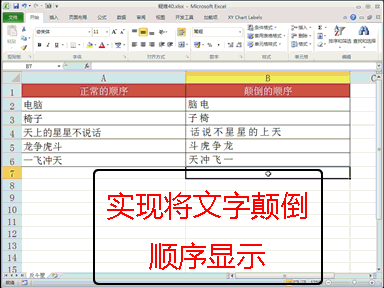
为了训练更强大的大型语言模型,研究者使用大量数据集,但数据来源信息常丢失,影响模型性能和引发法律伦理问题。 MIT团队对1800个数据集审计发现70%缺少许可信息,50%含错误信息。他们开发了“数据来源探索器”工具,自动生成数据集的易读总结。该工具有助于选择合适数据集,提升AI模型准确性,促进负责任的AI发展。研究还揭示正确许可常比存储库分配的更具限制性,且数据集创作者集中在全球北部,可能限制模型应用。为方便获取信息,研究团队构建了用户友好的“数据来源探索器”,允许下载数据来源卡。 未来计划扩展分析至多模态数据,与监管者讨论版权问题。这项工作改善了数据来源信息,对机器学习从业者在处理数据许可方面非常有价值。