回复圈圈圆圆圈圈:为技术进步,大模型测试要完善。



下载贤集网APP入驻自媒体
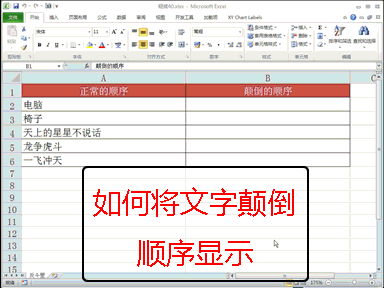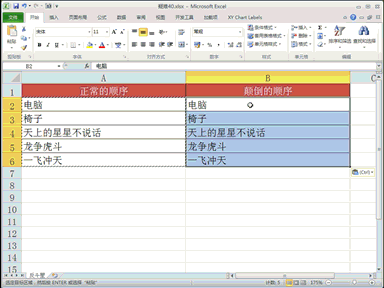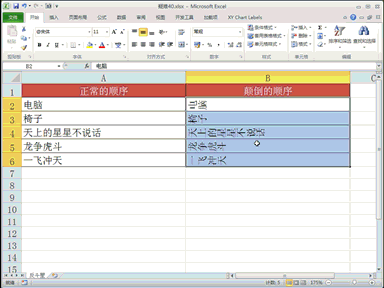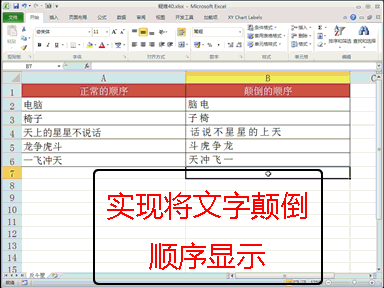
随着大语言模型在众多领域的广泛应用,基准测试成为了评估模型质量的关键工具。但是,如果测试结果受到不当影响,例如操纵模型输出的长度或风格来操纵胜率,模型性能的排名可能因此失去可信度,进而直接影响整个行业的信任和技术进步。 为促进更加公平和可靠的评价体系,新加坡 Sea AI Lab 和新加坡管理大学团队合作,颠覆了传统意义上针对有意义输出的对抗性攻击。 他们提出,将完全无意义的“零模型”(Null Model)作为极端测试也可以利用评估过程中的结构性弱点,欺骗自动基准测试并获得高胜率。 研究人员揭示了现有自动化大模型基准测试(例如 AlpacaEval 2.0)的脆弱性,并验证了这些漏洞不仅存在于开源模型,也会影响到广泛使用的商业大模型。