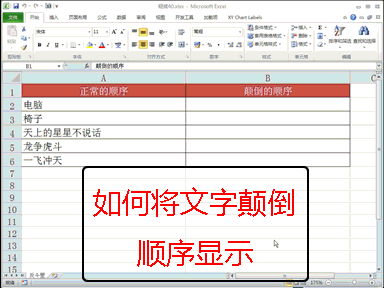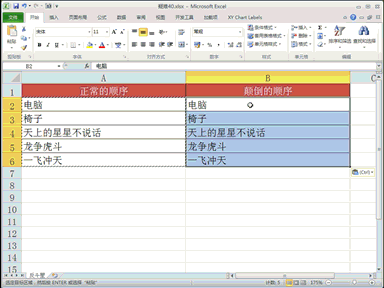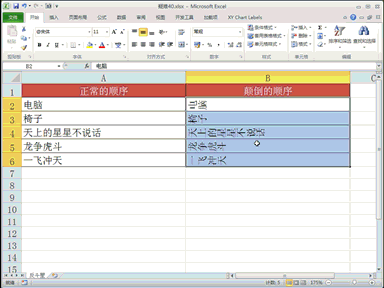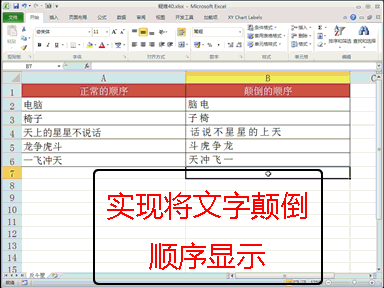
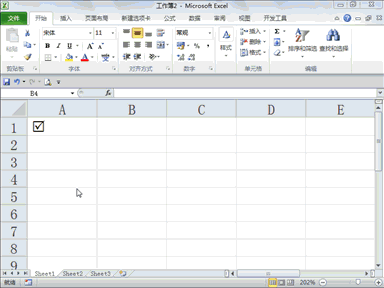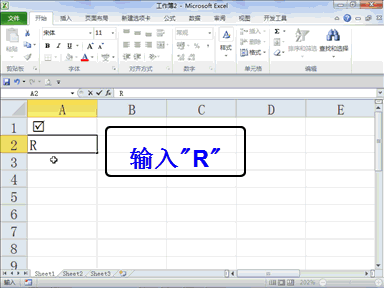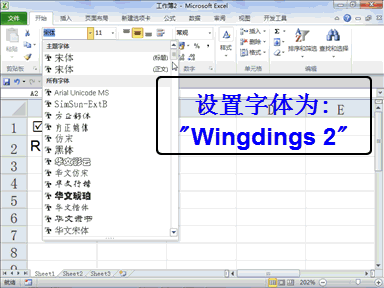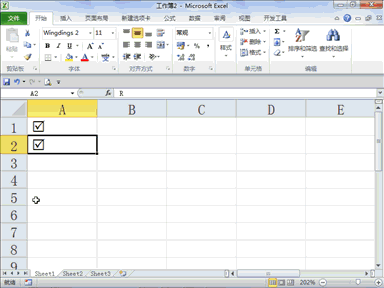
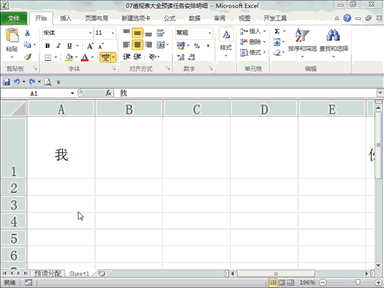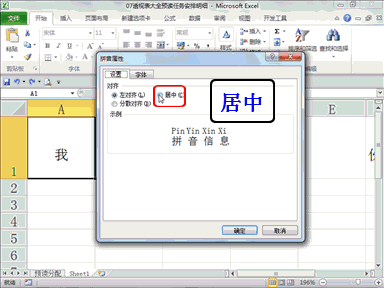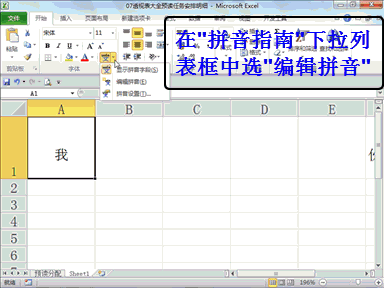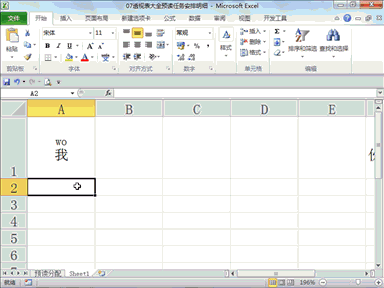
回复老刘说科技:做大模型时代的基础设施,是共识,尤其很多大公司都将这个领域视为必争之地,这意味着会面临着激烈的竞争。



下载贤集网APP入驻自媒体
2月18日,DeepSeek官方在海外社交平台X上发布一篇纯技术论文报告,主要内容是关于NSA(Natively Sparse Attention,原生稀疏注意力),官方介绍这是一种用于超快速长文本训练与推理的、硬件对齐且可原生训练的稀疏注意力机制。