回复黑科技看看:国产显卡加油!不奢望你比老黄强,只要你追上英特尔我就支持



下载贤集网APP入驻自媒体
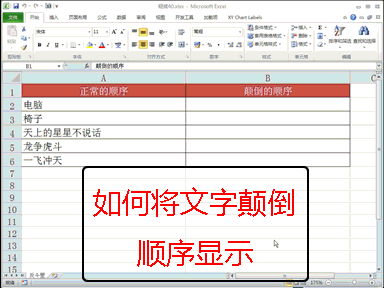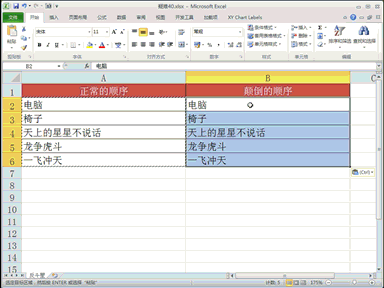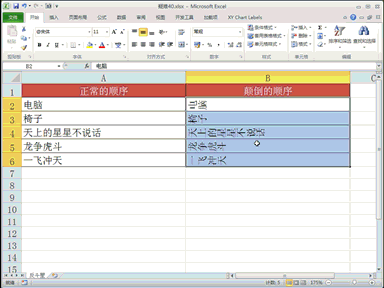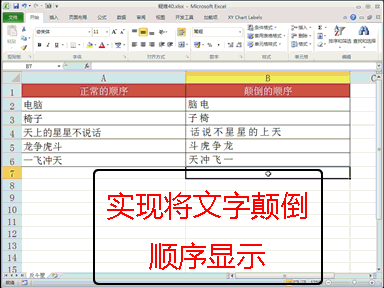
摩尔线程科研团队近日发布了一项新的研究成果《Round Attention:以轮次块稀疏性开辟多轮对话优化新范式》,使得端到端延迟低于现在主流的Flash Attention推理引擎,kv-cache显存占用节省最多82%。 摩尔线程认为,轮次块稀疏性有三大优势:自然边界的语义完整性、分水岭层的注意力稳定性、端到端的存储与传输优化。 测试显示,Round Attention的端到端延迟低于现在主流的Flash Attention推理引擎, kv-cache显存占用则节省55-82%,并且在主观评测和客观评测两个数据集上,模型推理准确率基本未受影响。