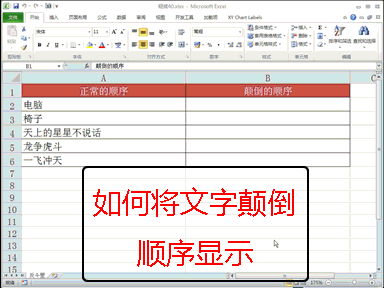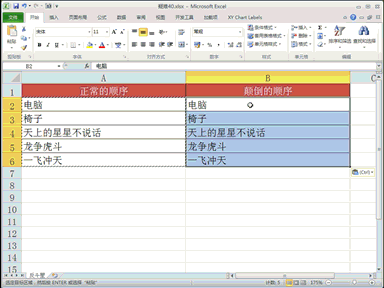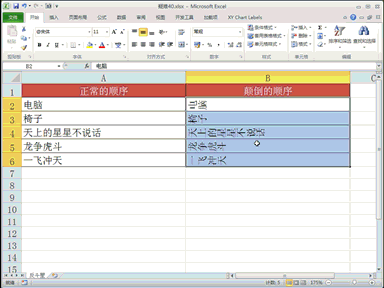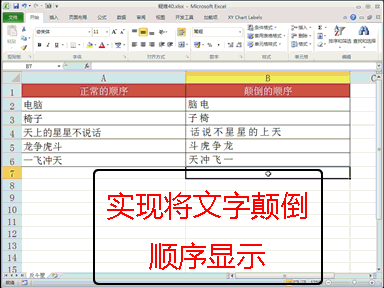
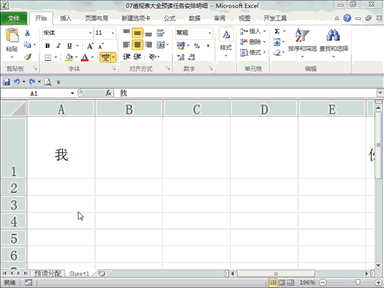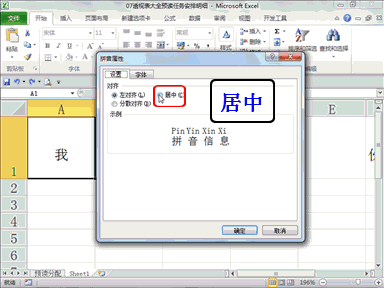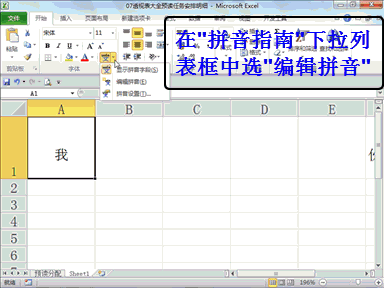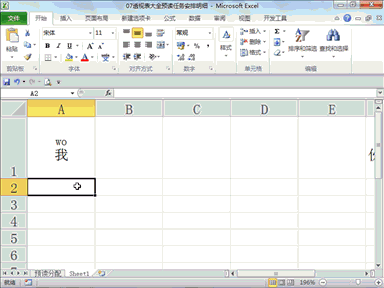
回复老刘说科技:将模型推理成本砍掉 83%,此次,又开源了 COMET,向模型训练成本出手。



下载贤集网APP入驻自媒体
字节跳动旗下豆包大模型团队近日宣布了一项关于混合专家(MoE)架构的重要技术突破,并决定将这一成果开源,与全球AI社区共享。 这一技术通过一系列创新方法,成功将大模型的训练效率提升了约1.7倍,同时显著降低了训练成本,降幅高达40%。这一突破为大规模模型训练提供了更高效、更经济的解决方案。该技术已在字节跳动的万卡集群训练中得到实际应用。内部数据显示,自采用该技术以来,已累计节省了数百万GPU小时的训练算力。