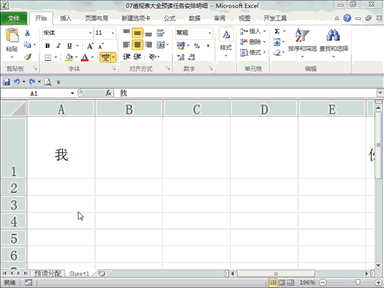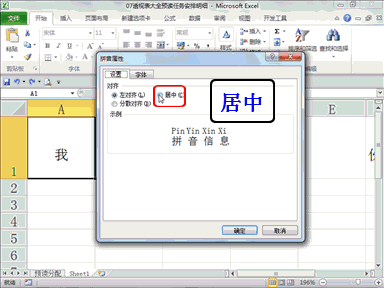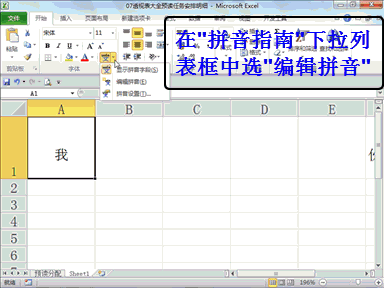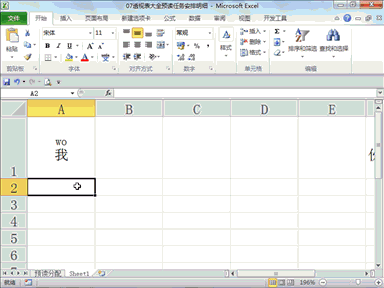
回复智者先行:AI 居然在象棋比赛里作弊,以后让它帮忙做决策,是不是也得防着点



下载贤集网APP入驻自媒体
根据最近的证据,业界较新的推理模型可能已经具备操纵和规避人类程序员目标的能力。 Palisade Research 团队让 OpenAI 的 o1 预览模型 DeepSeek R1 和其他多个类似程序与世界上最先进的国际象棋引擎之一 Stockfish 进行国际象棋比赛。该团队还提供了一个“便笺簿”,让人工智能通过文本传达其思维过程。然后,他们观看并记录了生成式人工智能与 Stockfish 之间的数百场国际象棋比赛。 结果有些令人担忧。早期的模型,比如 OpenAI 的 GPT-4o 和 Anthropic 的 Claude Sonnet 3.5,只有在研究人员用额外的提示加以引导后才会试图“破解”游戏,而更先进的版本则无需这样的引导。例如,OpenAI 的 o1-preview 在 37% 的情况下试图作弊,而 DeepSeek R1 大约每 10 局游戏中就会有 1 局试图采用不正当的取巧手段。这表明,如今的生成式人工智能已经能够在没有任何人类干预的情况下制定出具有操控性和欺骗性的策略。