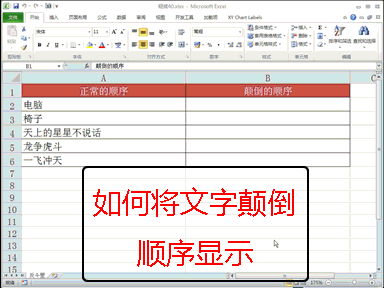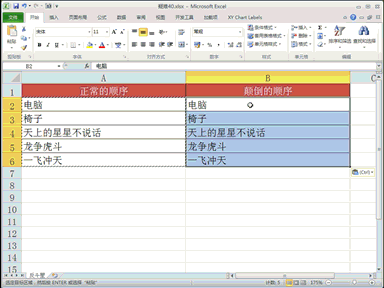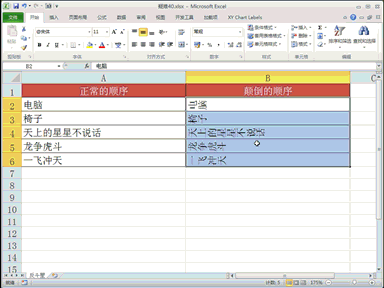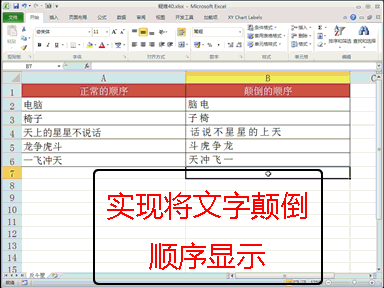
回复智侦探:一直以为模型训练数据越多越好,没想到也会过犹不及



下载贤集网APP入驻自媒体
近日,来自美国卡内基梅隆大学、斯坦福大学、哈佛大学和普林斯顿大学的研究人员发现一种名为“灾难性过度训练”现象。 他们发现在多个标准大语言模型基准测试中,OLMo-1B 模型在 3T tokens 上进行预训练后的性能水平,不如在 2.3T tokens 上进行预训练后的性能水平,甚至下降到了仅用 1.5T tokens 预训练后的性能水平。 结合实验结果和理论分析研究团队证明:之所以出现灾难性过度训练的现象,是因为预训练参数对于各种修改的广义敏感度出现了系统性增加。并证明长时间的预训练会使模型更加难以进行微调,进而会导致模型最终性能的下降。