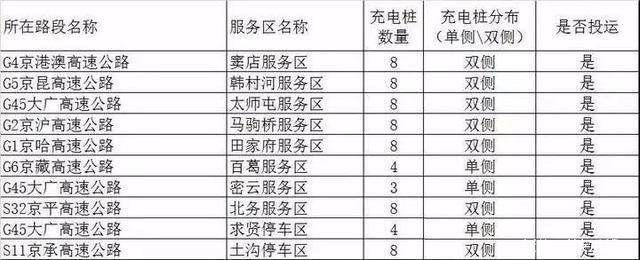
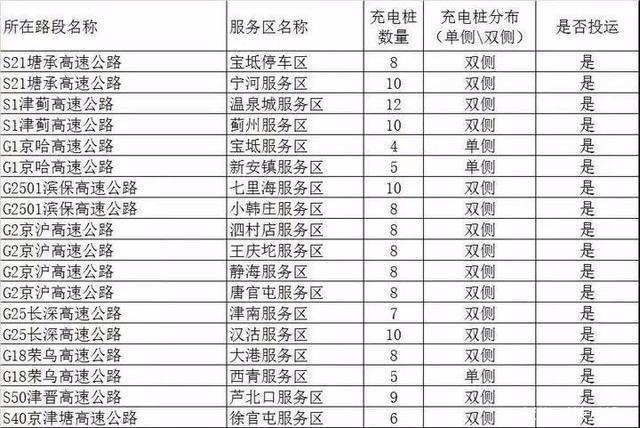
回复新材料前沿潜力股:理想汽车正研发VLA智驾大模型,目标今年下半年实现应用



下载贤集网APP入驻自媒体
3月10日消息,据媒体报道,理想汽车正在研发下一代VLA(视觉~语言~动作)智驾大模型,目标是于今年下半年实现项目落地。理想汽车在去年二季度财报电话会议上表示已启动端到端VLA模型的研究,将两个模型合二为一,使多模态大模型内化为端到端智驾大模型的一种能力。那么,VLA智驾大模型与此前的智驾系统有何区别呢? VLA智驾大模型结合了端到端和VLM(视觉语言)多模态模型的优势,能够提升智驾系统对复杂场景的理解能力,从而提高智能驾驶的精准度。与端到端大模型相比,VLM对图像和场景的理解能力更强,但端到端大模型存在决策不可解释以及难以处理部分场景的缺陷。