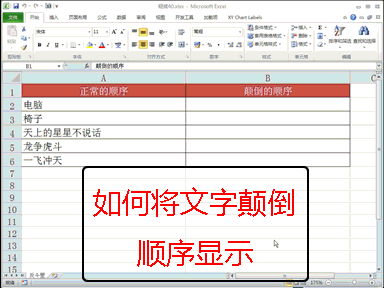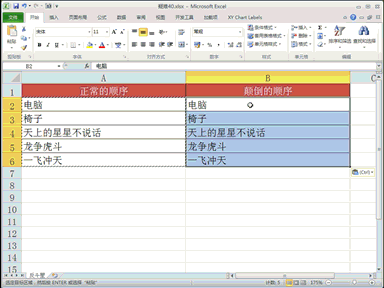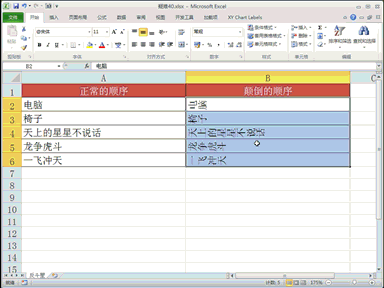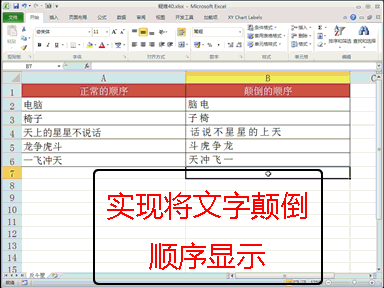
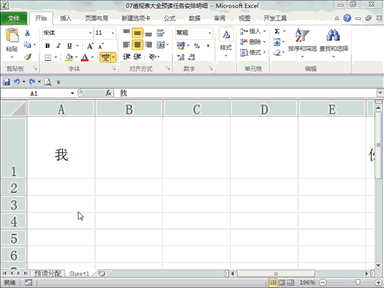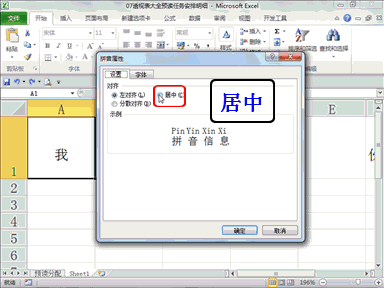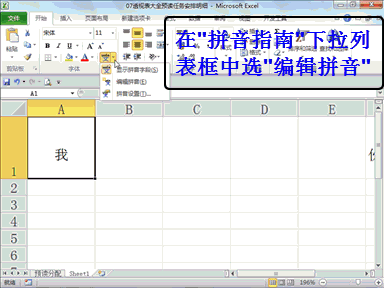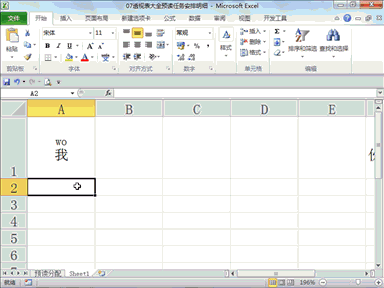
回复人工智能利弊说:看不太懂?直接大模型转成3D视觉



下载贤集网APP入驻自媒体
为了找到一个通用的向 3D 视觉迁移的方法,让不论哪种模态的大模型都能高效地理解点云数据,中国电信李学龙联合西北工业大学、北京大学、上海人工智能实验室的团队提出了 Any2Point,这是一个从任意模态迁移到 3D 的统一框架,能够通过参数高效微调(PEFT)将任意 1D(语言)或 2D(图像/音频)大型模型迁移至 3D 领域。与先前方法不同,Any2Point 避免了点云投影,从而减少了 3D 信息的损失,并直接对源模态的预训练模型进行微调,通过知识蒸馏节省了资源。 该项研究目前以“Any2Point: Empowering Any-modality Large Models for Efficient 3D Understanding”为题发布在 arXiv 平台上